Synaptic events fitting with user model¶
This Use Case allows a user to fit synaptic events using user’s data and model.
Selecting this use case, two Jupyter Notebooks are cloned in a private existing/new Collab. The cloned Notebooks are:
Synaptic events fitting with a user model - Config¶
It allows the user to:
Select a local experimental file
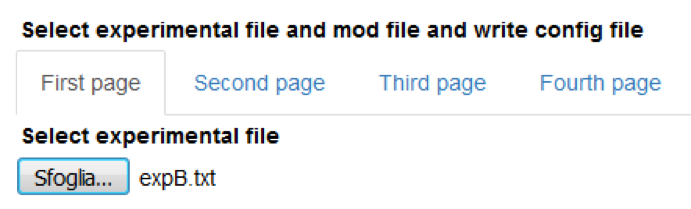
At this time, the only accepted format for the experimental file is a text file with time in the first column and individual traces in successive columns. All columns must be of the same length
Select a local mod file
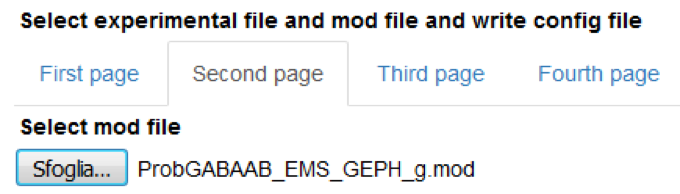
We assume that the user knows what we are talking about here, and that the uploaded mod file has been already tested by the user in preliminary simulations. The program does not perform checks on this. An invalid file will result in errors at NEURON compilation time
All other parameters that are not fitted have their default value as defined in the mod file.
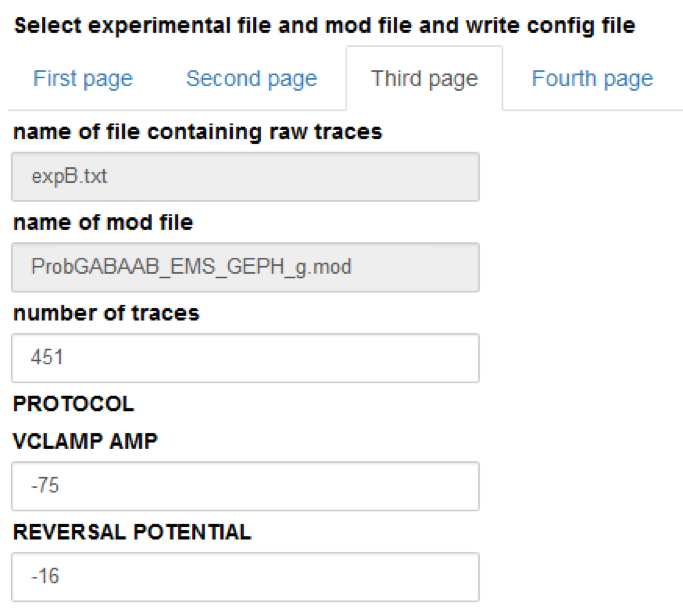
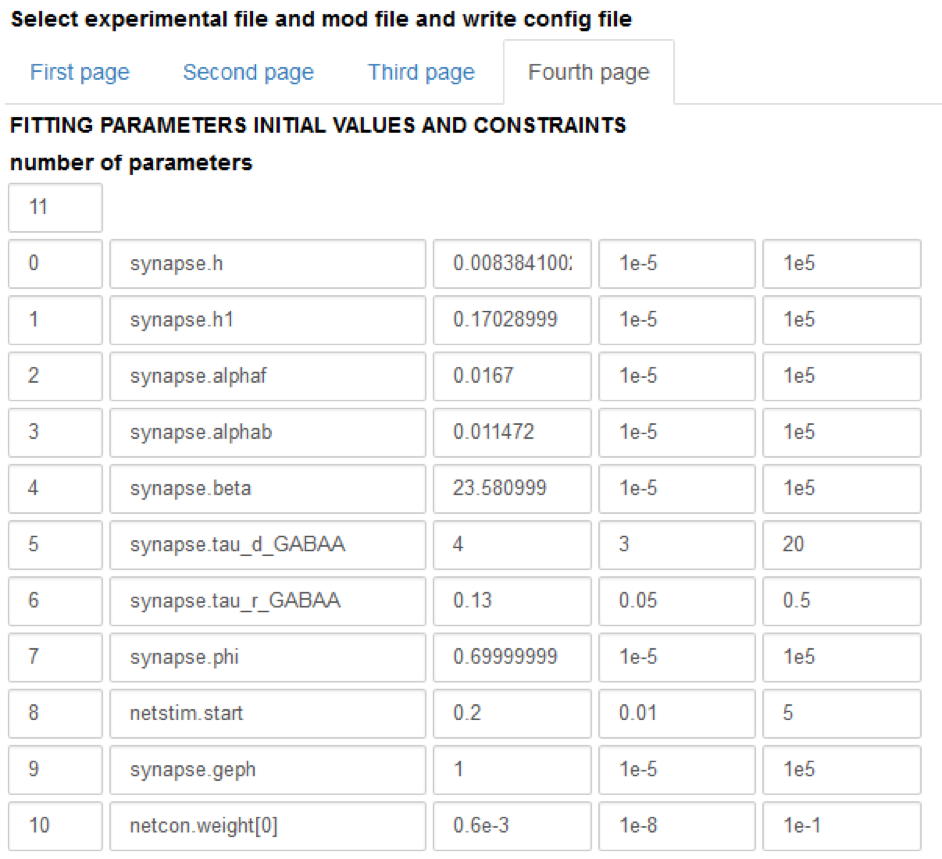
Fill in the form with the values needed to write a configuration file: the number of traces in the experimental file, the protocol (voltage clamp amplitude and reversal potential of the synapse), the name of the parameters to be fitted, their initial values and the allowed variation range, exclusion rules, and an optional set of dependencies for other parameters. Typical values are shown in the figure below

Configure the parameters of the optimization job: the title of the job, the number of nodes, the number of cores and the runtime. Run the fitting procedure using UNICORE authentication on JURECA (booster partition), GALILEO, or on NSG (using your account), and check the job status.
On JURECA the number of nodes, number of CPUs per node and runtime are set by default to 2, 24 and 10m respectively
On GALILEO the number of nodes, number of CPUs per node and runtime are set by default to 2, 36 and 10m respectively
The user needs to be aware of the limitations imposed by each HPC system on resources
On NSG the number of nodes, number of cores and runtime are set by default to 2, 24 and 0.5 (hours) respectively. The maximum number of nodes available per job is 72. If you require more than 72 nodes please contact nsghelp@sdsc.edu. The maximum number of cores required per node is 24.
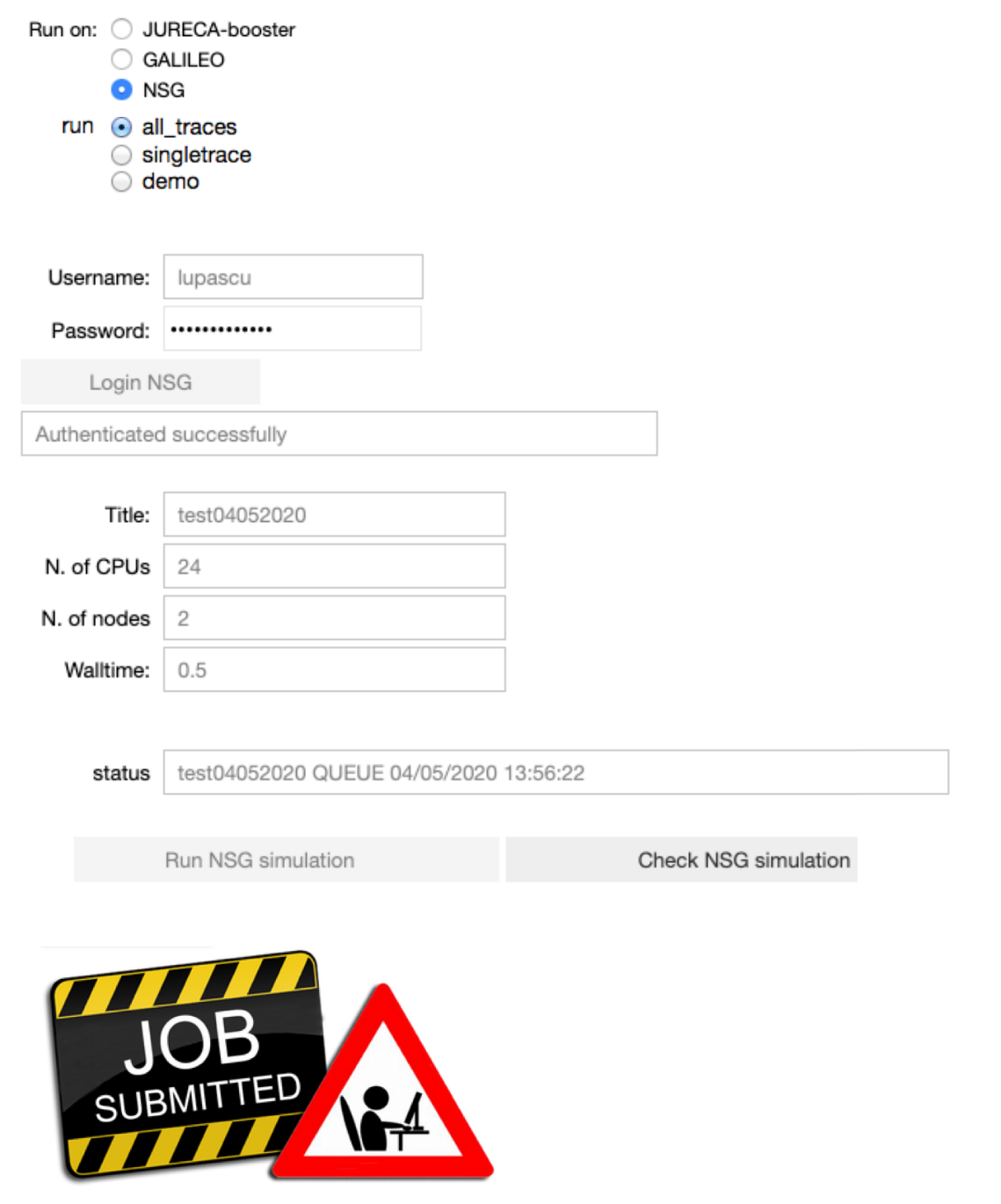
Note that when the job is submitted through UNICORE, the user can specify the project to use to submit the job on the HPC.

Note that when the job is submitted through NSG, the user can see the submission date converted to CET time next to the status of the job. This will be useful in the analysis notebook in order to fetch the job.
The user can choose to fit all experimental traces 100 times, a single trace 20 times or use a demo version where a trace is fitted 5 times. For the single trace and the demo version the user can choose the trace to be fitted.
Once the job is completed, the output files will be in the Collab storage under different directories, according to the system used.
JURECA: results are saved under the resultsJureca/jobtitle_fitting_submissionTime folder.
GALILEO: results are saved under the resultsGalileo/jobtitle_fitting_submissionTime folder.
NSG results are saved under the resultsNSG/jobtitle_fitting_submissionTime folder.
If you are interested in the code, click on the “Click here to toggle on/off the source code” button

If you want to start a new fitting from the beginning, click on the “Click here to start a new fit” button.
Synaptic events fitting with user model - Analysis¶
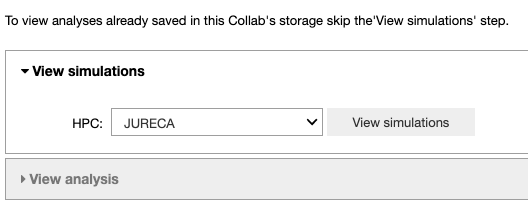
This Jupyter Notebook allows the user to fetch the fitting results from the storage of the HPC system to the storage of the Collab or to analyze the optimized parameters. If the user wants to view an analysis of simulations that are already in the storage of the Collab, (s)he can skip the ‘View simulations’ tab and go directly to the ‘View analysis’ tab.
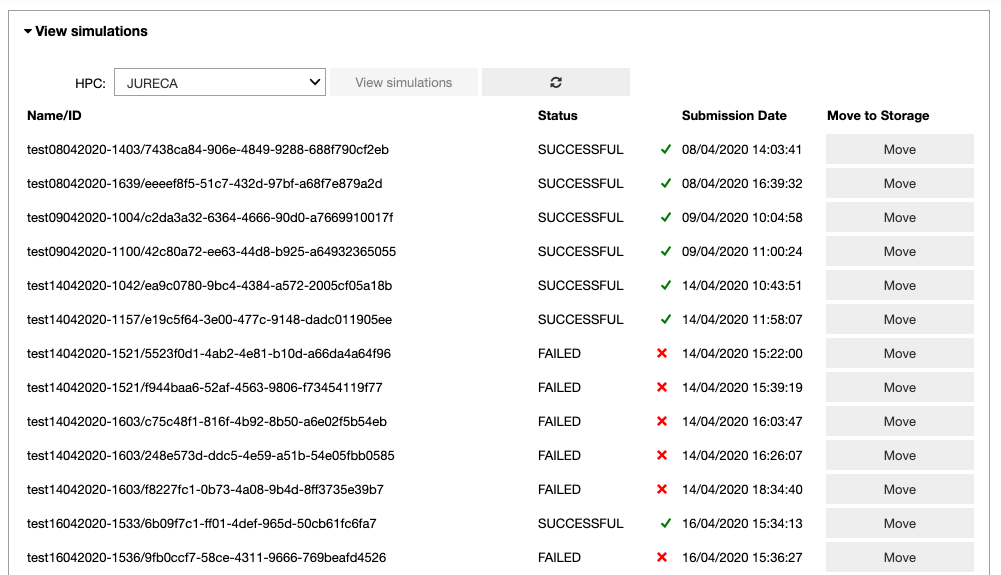
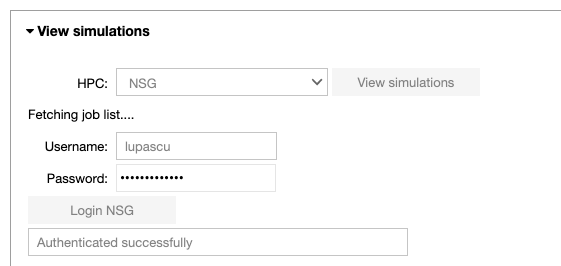
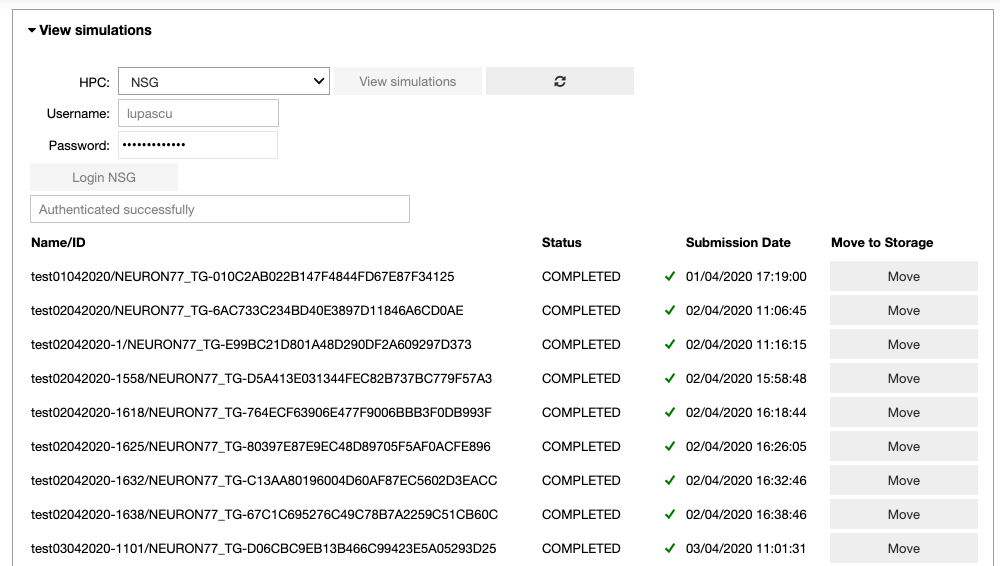
In the ‘View simulations’ tab, the user can visualize the Name/ID, status, the submission date of the simulations submitted on the HPC systems and (s)he can obtain an output of successfully completed jobs.
In the ‘View analysis’ tab, the user can analyze the optimized parameters for default data and a mod file combination or browse through the optimized parameters available in the Collab storage.
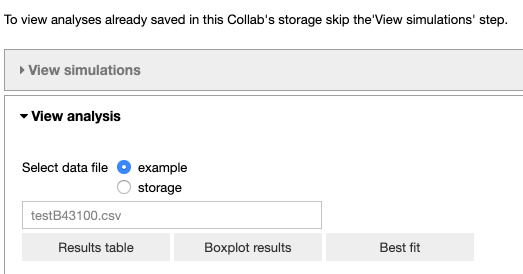
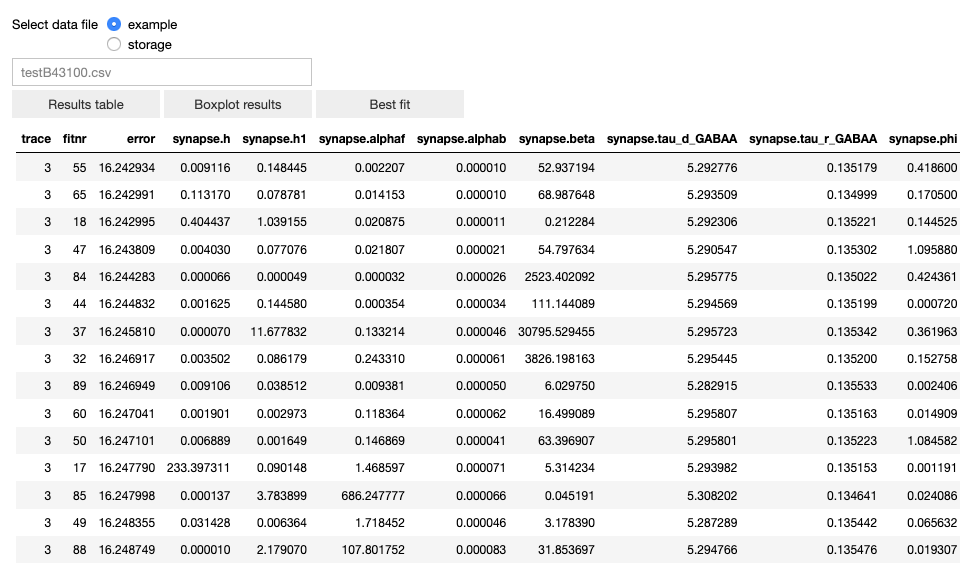
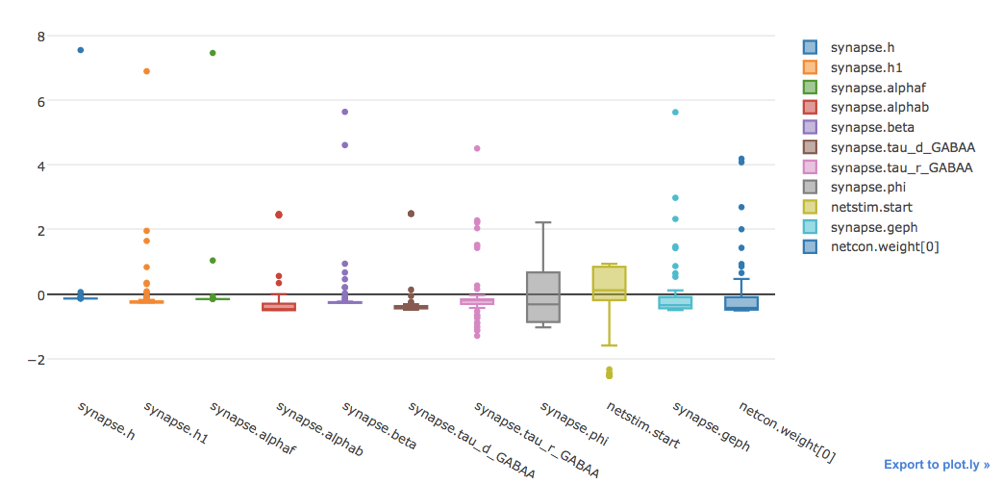
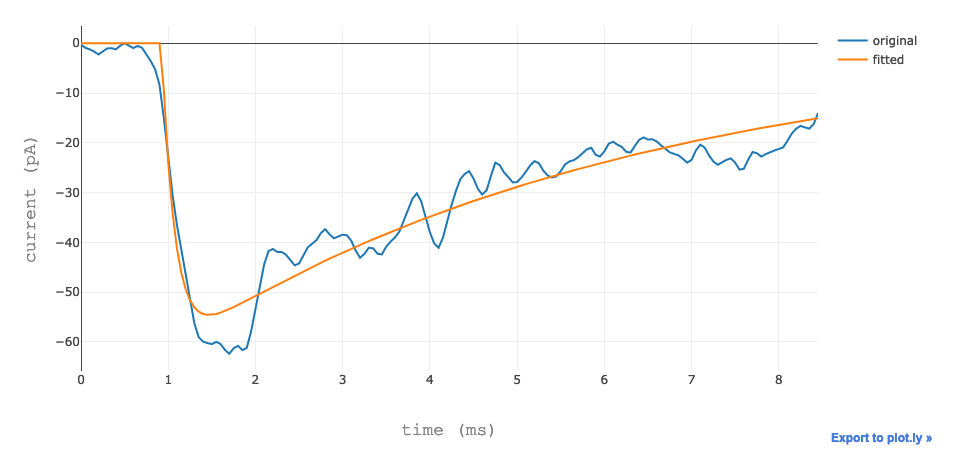
The user can visualize the data in table form, a box plot and the best fit.
The table of results (sorted in ascending order by the fitting error).
The boxplot of the normalized results.
The best fit.
If you are interested in the code, click on the “Click here to toggle on/off the source code” button.
